

I’m Tom Collins and I am Principal Software Engineer at the Driver and Vehicle Licencing Agency.
More specifically I work within Service Creation where we focus on digital product delivery across several major workstreams.

A software developer is a multi-disciplined person who is capable of designing, developing, maintaining, updating, testing, and evaluating software systems and processes. You may work on services used directly by millions of citizens or APIs used by vehicle retailers and the emergency services. You may be involved in writing computer programmes from scratch or amending existing “off-the-shelf” programmes to meet the needs of a project.
Working with data formats at the DVLA
This is going to be a fairly technical post about how we manage and work with data formats at the DVLA. This is an area we’ve really invested in over the last few years, building tooling and processes that make heavy use of JSON Schema.
What is JSON Schema?
JSON Schema (json-schema.org) is a standard vocabulary that allows developers to describe data formats. At the DVLA we use these definitions in various ways e.g. to generate human friendly documentation, to generate code based on the models, to describe parts of our API interfaces and to validate data objects.
In this post we’ll explore each of these stages in a bit more detail.
Describing our data formats
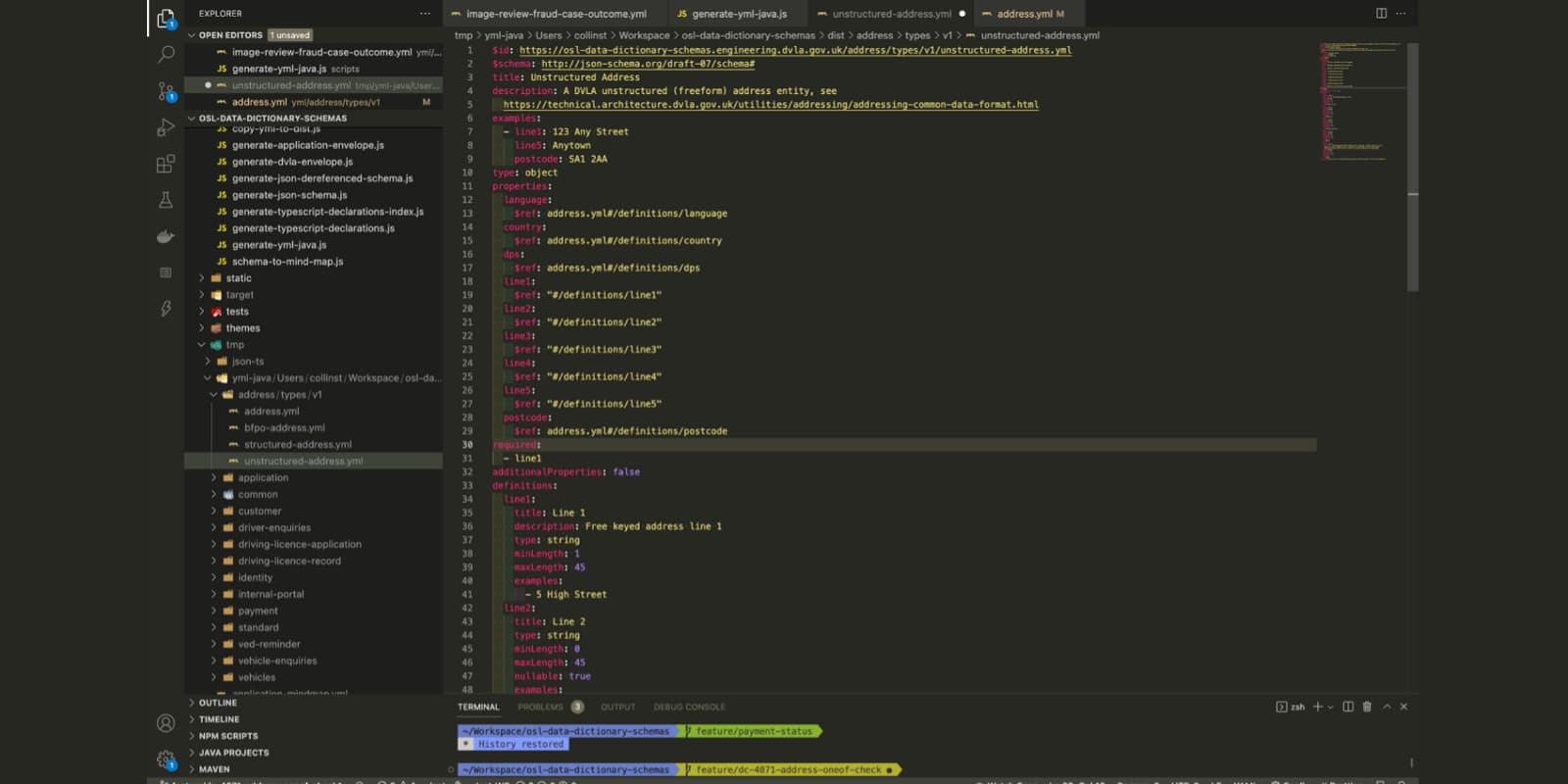
We use a shared code repository to describe our data models using JSON schema. These take the form of yml documents, organised around the structure of our product teams, for example Driving Licence, Vehicles or Payments.
Within each product we define various different types of data:
- the core data types e.g. a driving licence or entitlement
- any request, response and message formats
- additional data types such as applications, events and actions
For each data type can define validation constraints such as mandatory properties, min and max lengths etc. We can also use references to compose schema so we can have a single definition of a property such as a registration number, and then use this in multiple places without duplication.
We also have a set of test and build scripts that help ensure consistency and quality including requiring all schema to pass validation and adhere to certain naming conventions. We also ensure each schema contains at least one example, that passes validation, as this really helps with documentation.
Collaboration and Peer Review
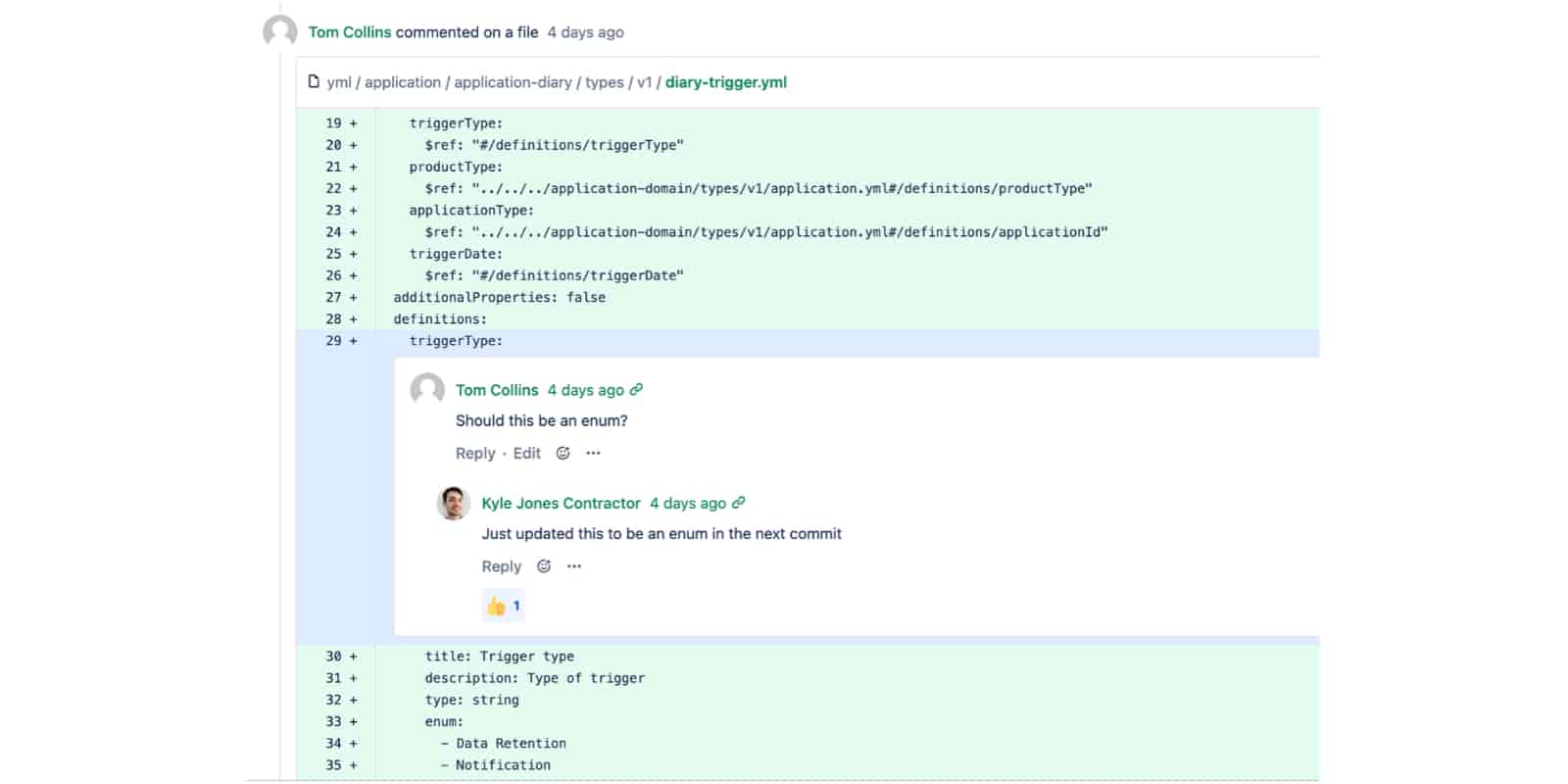
Peer review forms an important part of the process and is an opportunity to review, discuss and improve our data models. This all takes place collaboratively and openly before we write any code, which we have found to really increase efficiency and quality.
This process often generates insightful questions that help develop a clear understanding of the data and system we are designing, for example:
- what does this piece of information really represent?
- what is this property used for?
- do we really need this property?
- what information do clients need to provide or consume?
Human-friendly documentation

We use the open source json-schema-static-docs library to generate markdown versions of our schema definitions. This are published as a static website, using the hugo framework, and made available to developers and other stakeholders.
This has become the source of truth for our conceptual data models and has increased collaboration, consistency and reuse of data models and schema. The open nature of the documentation means that product teams can easily view and understand the data types used by other teams which helps drive out consistency of approach, naming, structure etc. A lot of this can happen before any code or API contracts are created which has increased efficiency. But fear not, this remains an iterative agile process, and is not all done up-front.
Sharing schema and Open API
As part of our build process we publish an npm package containing yml and json versions our schema to our internal repository. We also generate a de-referenced version of the schema using json-schema-ref-parser as this makes it easier for other tools to consume the schema.
This all allows our teams to use the schema within their processes and applications to do things like:
- reference schema entities and properties within OpenAPI specifications (json-schema and OpenAPI have been compatible since OpenAPI3.1)
- use schema definitions to validate data objects within their applications (shout out to the awesome AJV validator)
Code generation
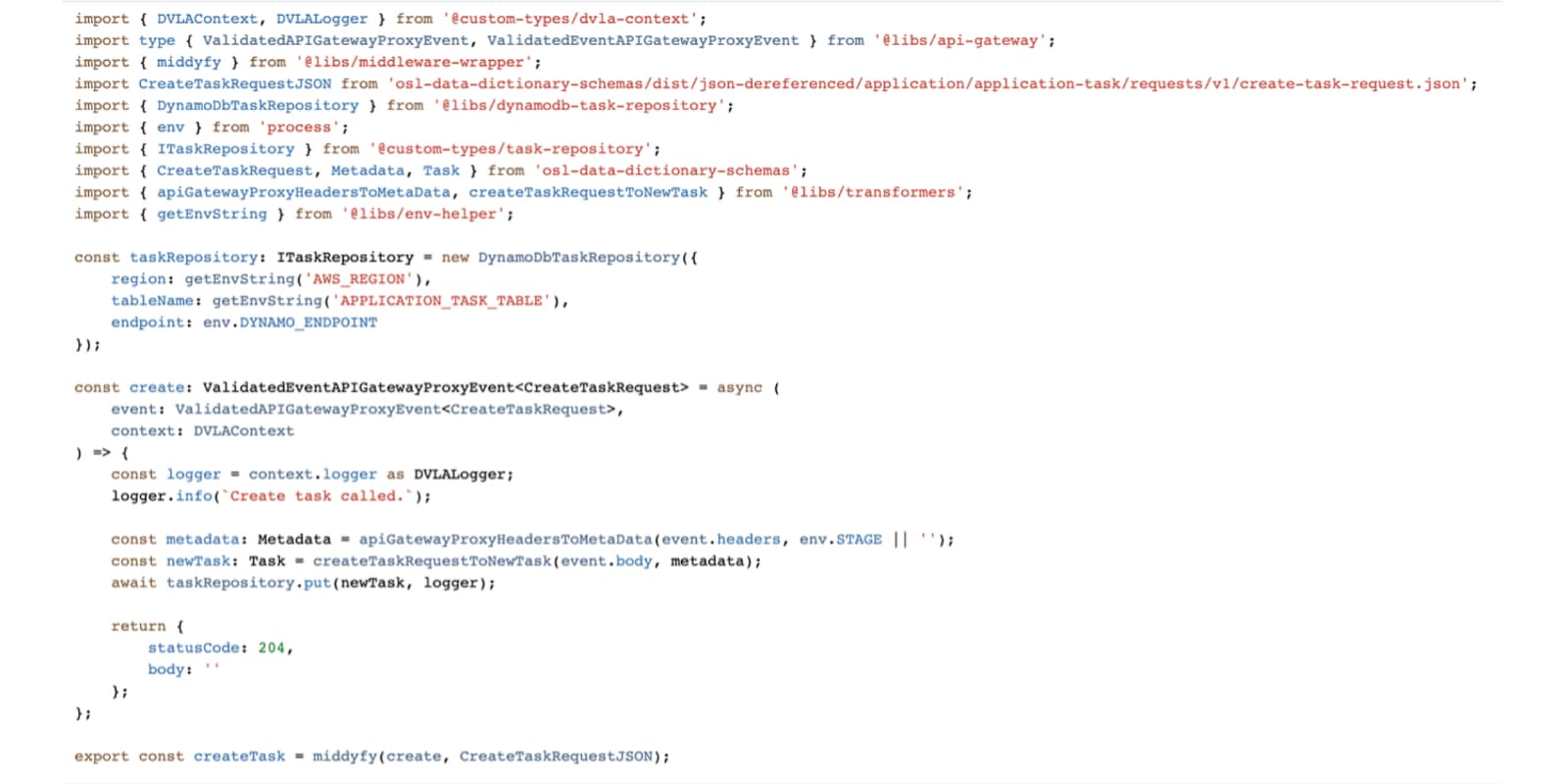
Finally, our build process includes code generation steps that creates representations of our data models in Java and TypeScript. This allows teams to import the generated code into their applications to give them strongly typed models, making it easier to work with data and reducing the opportunity for various types of error.
The Java code generation step creates Java classes using the jsonschema2pojo utility which gets published to our internal maven repository. For TypeScript we generate interfaces using json-schema-to-typescript and these get bundled with the schema in an npm package.
Conclusion
Hopefully this has provided some useful insight into our processes for working with data at the DVLA. We’re always looking for ways to improve our approach, and keep up with changes to specifications and the tools we use, but think this is a great use of data schema that improves the quality of our data and our developer experience.
Visit DVLA Digital profession pages for more information on the Software Developer role at DVLA.
You can find all of DVLA’s current vacancies on Civil Service Jobs, where you can search for roles, sign up to job alerts, apply and monitor application progress.
This article was written by Tom Collins, Principal Software Engineer


