

Automation Testing plays a crucial role in DVLA. From delivering DVLA’s IT Services, to building the Agency’s best-in-class automation software. Take a deep dive into the work our Automation Testing teams do, and see how you could fit in our award-winning Digital team in the upcoming Software Development Engineer in Test (SDET) Academy.
Kicking us off is DVLA’s own Nigel Brookes-Thomas, Principal Quality Engineer. Keep reading as Nigel reveals the ‘secret sauce’ and the guiding principles that make up the foundations of DVLA’s automated testing code and their creative digital team.

Nigel Brookes-Thomas, Principal Quality Engineer at DVLA
“The software development process at DVLA is genuinely cutting-edge. There’s nowhere else I would be able to get exposure to all the different technologies we’re using here.”
Hi Nigel, can you tell us a little about what your team does?
DVLA have a cohort of experienced Software Development Engineers in Test (SDETs). These are software and testing professionals who write code to automate the testing of application code. My team sits within IT Service Creation, building and operating digital services for the public, partners, and agency.
We value our automation code as highly as our production code, it’s the secret sauce that lets us make changes quickly and safely.
Our principles
What are the core principles of automation testing?
We have a small number of guiding principles which drive how we build all our automation:
- Test early, test often
- Each test is an island
- Data factories over fixtures
- Stub almost nothing
Test early, test often
We test as early as we possibly can, so the automation is built on the same branch as the application code since the acceptance criteria of a change are used to focus our testing. Tests run on each push, meaning changes can only be merged into the mainline when the tests pass which also triggers another, fuller, regression suite.
We use Gherkin syntax to reach a shared understanding of the change and put a lot of effort into writing these elegantly. Our house-style helps us along with a linter, used to automatically check we are following that style. For instance, every feature must be tagged with its Jira ticket and every scenario named to identify the acceptance criteria it covers.
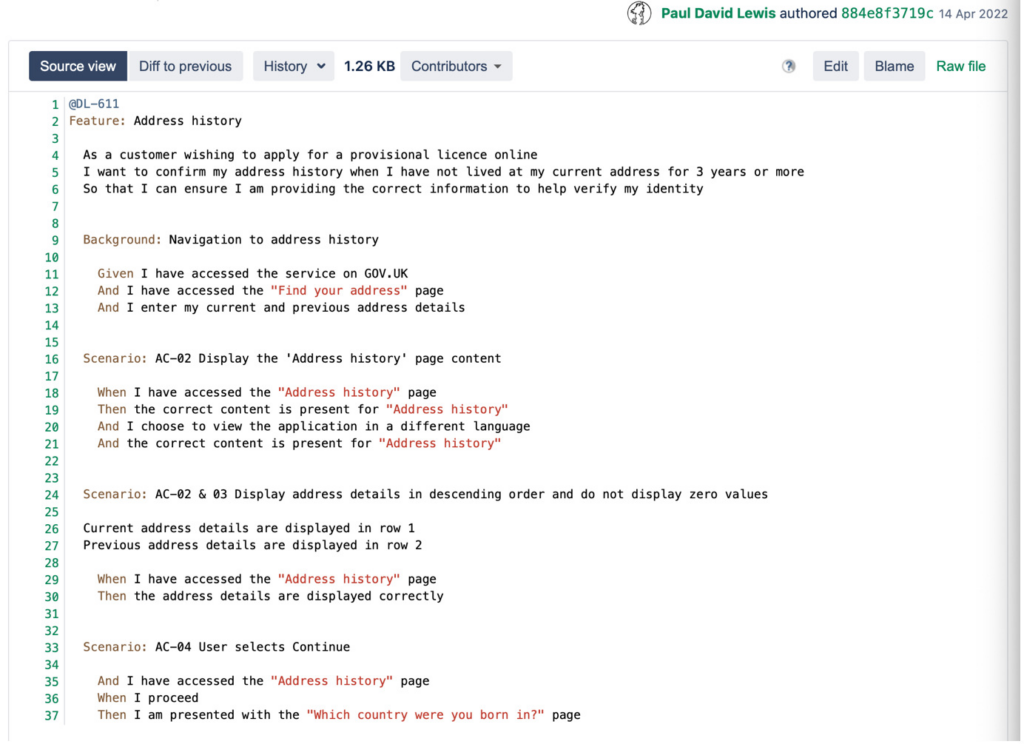
We want changes to be safe, but we also want them to be fast, so we commit time to ‘gardening’ – trimming our tests to focus on the risk of a change and avoiding duplication.
Each test is an island
Each individual test must be isolated from every other one. This lets us run the test pack in any order or to choose to run just a single scenario on its own. Each test sets up and tears down its own data.
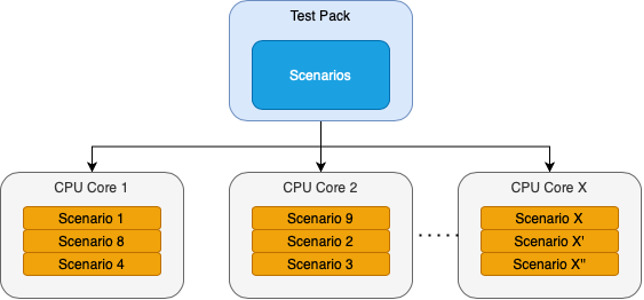
In practice, this is important because we slice up the test pack and distribute scenarios over many processes to run the pack in parallel. No one test can rely on any other running before it or after it.
It also allows us to run variations of our tests, such as testing localisations to different languages.
Data factories over fixtures
Fixtures are sets of data which are built in advance and used for testing. It’s hard to build and maintain large sets of fixtures. It’s challenging to build convincing sets of data that look like real world data. For this reason, we use synthetic data that is uniquely generated on each test run by factory objects which assemble data on the fly. This detects more failures as each run is a real test, not just a check, giving the application-under-test data it has likely never seen before.
Of course, we save the data that’s been built by the factories so we can trace failures and in early builds we can see flakiness as the application encounters data and combinations it hasn’t seen before. We are also making the application more robust in the process by running these tests early.
Stub almost nothing
A stub is a piece of code used to stand in for some other programming functionality.
Stubs pretend to be real services and offer a chance to test an application without having a dependency. In practice, we have found stubs to be rather unloved components with their own defects and deviations from the service they pretend to be. Unless it’s impossible or expensive, we almost always choose to avoid them and use real services instead.
Our applications and services are dockerized or serverless: we don’t need to build and maintain stubs; we can use the real services instead. Our continuous integration (CI) tooling can launch containers and with minimal effort and time, we can bring up entire application stacks and dispose of them after each test run. For each run, we are not just performing component or feature tests, we’re running real integration tests at the same time. This is a significant risk reduction because we can check behaviour as downstream components change.
Finally, our pre-production environment is running system integration tests daily over the estate, checking that all our systems co-exist and integrate together.
Conclusion
I’m hopeful that this has given you some insight into the way automation testing happens at DVLA. We are always looking to push more testing early in the development cycle and we believe our principles guide us in testing complex systems while reducing the risks that come with change.
For more information on the Software Development Engineer in Test role at DVLA, visit our new DVLA Digital profession page.


